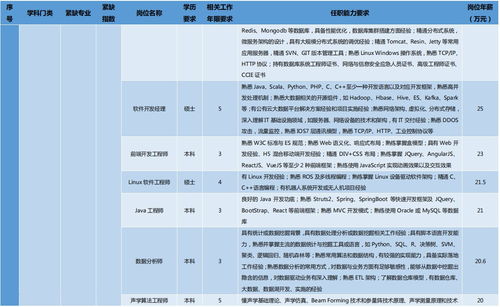
首頁 > 產品大全 > 新點軟件榮膺“2019年中國最具影響力軟件和信息服務企業”獎項
如若轉載,請注明出處:http://m.masajex.com/product/32.html
更新時間:2026-06-19 06:39:00